인공 지능은 모든 산업과 업종에 걸쳐 사용되고 있으며 보편적인 요구 사항으로 자리 잡고 있습니다. 머신러닝 및 자연어 처리(NLP)와 같은 업무별 Al 모델을 사용하여 지속적으로 들어오는 데이터를 분석하여 인사이트를 얻고 실시간 의사결정을 지원하는 데 있어 Al 기반 솔루션은 필수적입니다.

GenAI(생성형 AI)를 위한 인프라 요구 사항
대규모 GenAI 모델은 초저지연 메모리 및 스토리지 시스템에서 액세스하는 수십억 개의 파라미터가 포함된 테라바이트(TB) 크기의 학습 데이터 세트를 지원하기 위해 방대한 양의 GPU 지원 컴퓨팅을 필요로 합니다. 이러한 대규모 GenAI 모델을 지원하는 네트워크는 LLM 멀티테넌트 워크로드 환경 전반에서 최적화되고 전력 효율적이며 예측 가능한 성능을 제공하도록 맞춤화됩니다.
컴퓨팅, 데이터 처리 장치(DPU), I/O, 케이블 및 광학, 가속 소프트웨어, 네트워크(예: InfiniBand 400/800G 이더넷 스위치) 등 네트워크의 모든 측면이 전체 시스템을 지원하도록 패브릭과 토폴로지가 고도로 조정되어 있습니다.
AI를 위한 데이터센터 네트워크 준비
AI 아키텍처에는 가장 빠른 학습, 추론, 모델링 작업 완료 시간을 보장하기 위해 고성능과 저지연 연결성을 결합한 전용 네트워크 패브릭이 필요합니다. 초기 HPC 및 AI 트레이닝 네트워크에서는 서버와 스토리지 시스템 간의 빠르고 효율적인 통신을 위해 초기에 고속, 저지연, 전용 InfiniBand 네트워크가 인기를 얻었습니다.
오늘날 100/200/400G+ Leaf/Spine 이더넷 스위칭은 개방형 표준 기반의 대안 옵션을 제공하여 HPC/AI 클러스터의 네트워킹을 지원하는 데 상당한 추진력을 얻고 있으며, 많은 AI 사용 사례에서 가장 저렴한 비용으로 대중적인 대안이 될 것으로 예상됩니다.
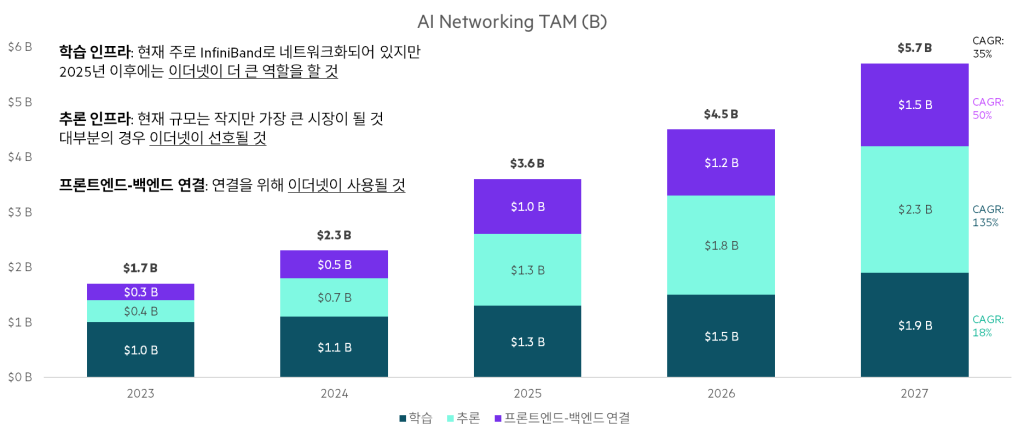
“AI의 대역폭이 증가함에 따라 AI/ML 및 가속 컴퓨팅에 연결된 이더넷 스위칭의 비중은 2027년까지 시장의 상당 부분으로 이동할 것입니다. AI/ML을 지원하는 제품이 생산 규모에 도달하는 대로 800Gbps 기반 스위치와 광모듈의 출하량이 기록적인 수치를 기록할 것입니다.”
650 Group의 설립자 겸 기술 분석가, Alan Weckel
최신 AI 애플리케이션에는 100G에서 400G 이상의 고속으로 수백 또는 수천 개의 GPU를 상호 연결하는 고대역폭, 무손실, 저지연, 확장 가능한 멀티테넌트 네트워크가 필요합니다. 이더넷 기반 네트워킹 패브릭은 수백에서 수천 개의 GPU가 있는 AI 워크로드 클러스터에 필요한 안정성과 성능을 제공합니다.
AI 패브릭 네트워크에서 Backend vs Frontend 차이
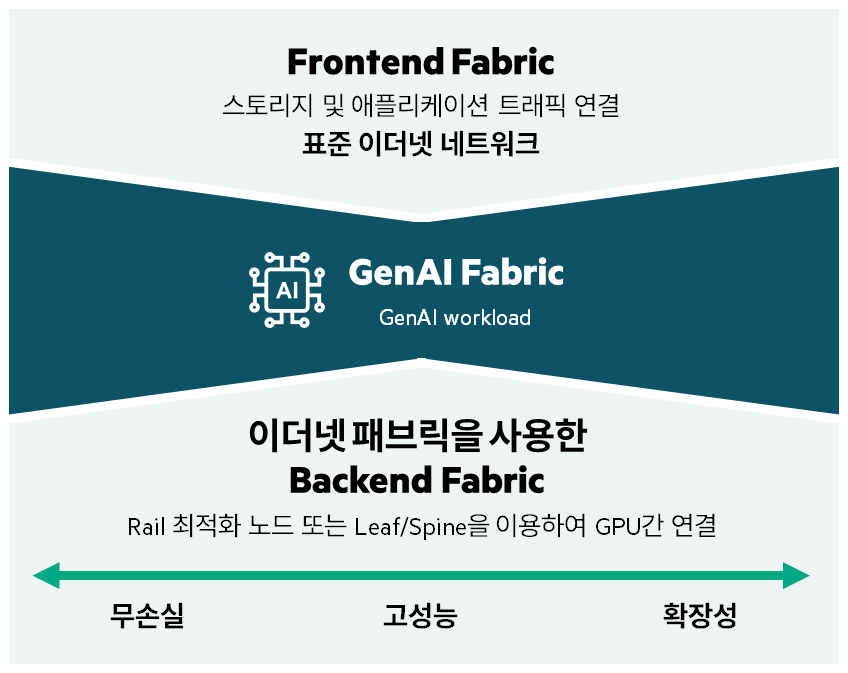
- Frontend 네트워크: 기존 이더넷 네트워크를 활용하여 구축하며, 공유 스토리지를 지원하기 위해 무손실 환경으로 구축
- GenAI 패브릭: GPU가 내부 PCIe 버스와 백엔드 패브릭을 모두 사용하여 워크로드 트래픽을 이동하는 워크로드로 구성
- Backend 네트워크: AI 서버/워크로드를 서로 연결하는 데 사용하며, 전용 스토리지도 포함될 수 있음. 워크로드와 패브릭 간에 Link Oversubscription 없는 상태로 구축하고 Low Latency, DCB, RoCE 등을 사용하여 GPU 워크로드에 최적화한 환경
GenAI Backend 패브릭 네트워크 설계 방식
Multi-layer Clos
- ToR 스위치는 각 서버를 연결하고 집선 스위치를 통해 다른 랙에 연결을 제공
- Spine 스위치는 다른 POD에 대한 연결을 제공
- CPU 사용량이 많은 워크로드에 가장 적합
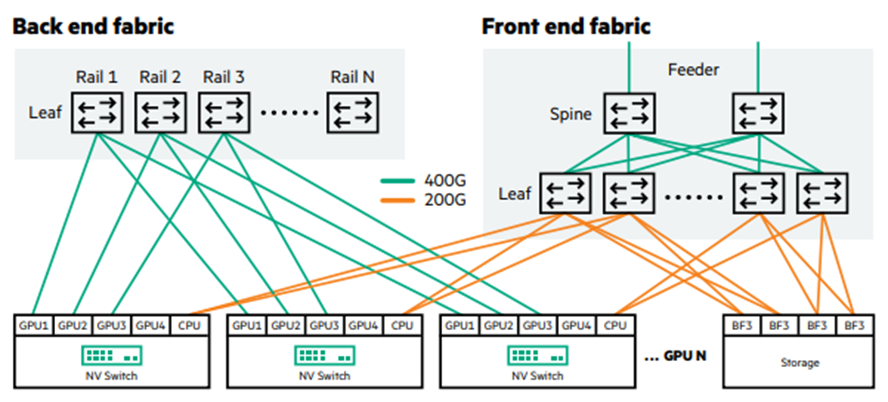
Rail Optimized (레일 최적화)
- 각 GPU에 두 개의 서로 다른 통신 경로가 있는 GPU 중심 클러스터를 기반으로 구성
- 한 경로는 NVIDIA® NVSwitch1를 통해, 다른 경로는 레일 스위치를 통해 연결
- 개별 서버의 NVIDIA NVSwitch는 고속 상호 연결을 생성하여 고 대역폭(HB) 도메인을 형성
- 이러한 레일 스위치는 Spine 스위치에 연결되어 전체 구간, Any-to-any Clos 네트워크 토폴로지를 형성
Rail Only (레일 전용)
- Rail Optimized와 유사
- 대신, Rail 안의 다른 랭크(Rank)의 GPU간 네트워크 연결 제거
- HB 도메인2을 통해 데이터를 전달하여 통신은 여전히 가능
HPE Aruba Networking의 AI 지원 데이터센터 스위치
HPE Aruba Networking은 전용 AI 네트워크 패브릭을 설계하고 구축하는 데 도움을 줄 수 있습니다.
HPE Aruba CX 8325 스위치 시리즈

CX 8325 스위치 시리즈는 1/10/25/100GbE 포트를 지원하는 엔트리급 GenAI 스위치 솔루션입니다.
Rail-only 아키텍처를 지원하며, 최대 6.4Tbps 1U 스위치로 일반적인 데이터센터 환경에서도 적합합니다.
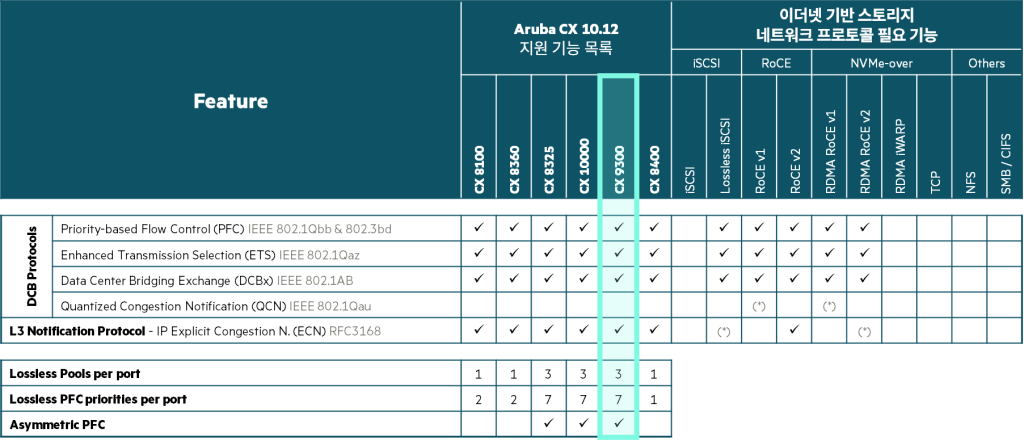
HPE Aruba CX 9300 스위치 시리즈
CX 9300 스위치 시리즈는 차세대 25.6Tbps, 1U 스위치로, 32개의 100/200/400GbE 포트를 지원합니다.
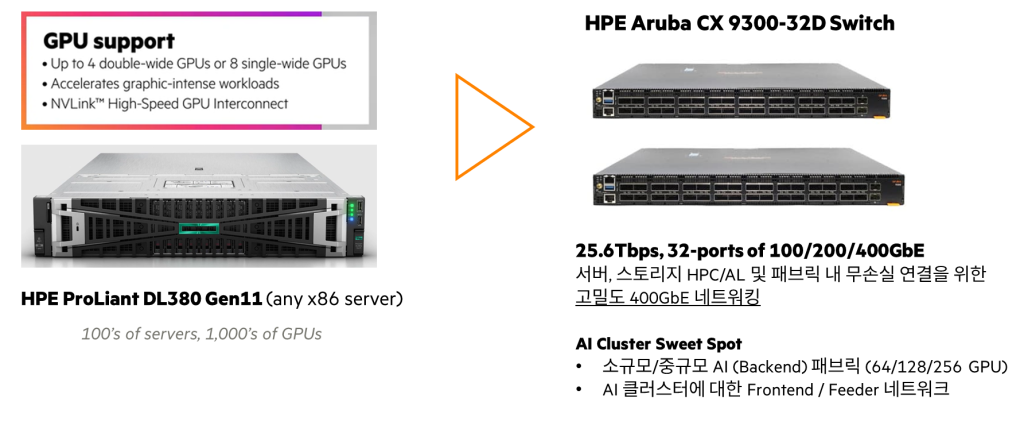
CX 9300은 짧은 지연 시간, 무손실 네트워크 서비스 품질(QoS), ROCEv2, ECN, PFC 등 AI/HPC에 필요한 연결 특성 등 AI/HPC 최적화 기능을 제공합니다. 또한, Rail-only 및 Rail-optimized 아키텍처 모두 지원하며 CX 9300 스위치는 Spine 또는 Rail 목적으로 사용 가능합니다.
보다 자세한 정보는 아래 링크를 참조하세요.


